A program that downloads movies! | Програма яка завантажує фільми!
Я не закликаю вас піратити та використовувати такий метод, я хочу лише показати спосіб як можливо це робити. Завжди користуйтесь тільки офіційними джерелами які мають усі права. Усе що вказано у цій статті та наступних щодо цієї теми виключно у навчальних заходах і є противоправними діями!
I don't encourage piracy, just showing a way it could be done. Always use official sources with proper rights. Everything in this article is for educational purposes only and considered illegal actions!
Hello everyone, I'm not a pirate, and I never was. However, it became annoying to reload pages while watching movies due to constant connection issues caused by my poor internet. Films from websites don't download fully while on pause; it's only about 5 minutes, sometimes 15-20 minutes. But if the connection is interrupted, it stops. Torrents aren't an option either since distributing non-licensed content is prohibited by law.
So, let's get back to the topic. How does movie downloading work? It's not a single large file as we're used to seeing (3-8 gigabytes); it consists of small pieces encoded as byte strings in the received packet, typically about 30 seconds per data packet. There can be many of these pieces, several thousand per movie (imagine how many server requests are involved). First, your browser sends a GET request to the server, receiving a byte string containing a segment of the movie, including audio and subtitles (so when you click the subtitle button, they may not appear immediately). The player has an algorithm to decode this byte string, play the video file, sound, and subtitles, placing it all in RAM (hence why a YouTube tab can use 1.5 gigabytes).
Knowing this, we need to start with some service as our basis. I'll use the familiar HDRezka but will write 'domain' instead of a link to avoid promoting it. The algorithm itself is quite simple. The first step is to find a search query for movies:
uri: domain/engine/ajax/search.php,
PARAMS:
{
"q": "Terminator"
}
In response, we get the movie title and the link to its page. But it's in HTML format. Next, I used the 'bs4' library to parse the HTML we received. In the link, there's a code for the movie corresponding to the database entry, 'domainfilms/horror/57276-astral-5-krasnaya-dver-2023.html.' We're interested in that '57276,' but more on that later. All the information about each movie, localization, etc. is already available here (smart architecture, right?), making the next operation simpler.
With all the necessary input data, we move on to the next GET request, which I found after going to the movie page:
uri: domain/ajax/get_cdn_series/?t=timestamp
PARAMS:
{
"id": ,
"translator_id": ,
"favs": ,
"season": ,
"episode": ,
"action": ,
}
After this request, we receive the same links for each part of the required movie.
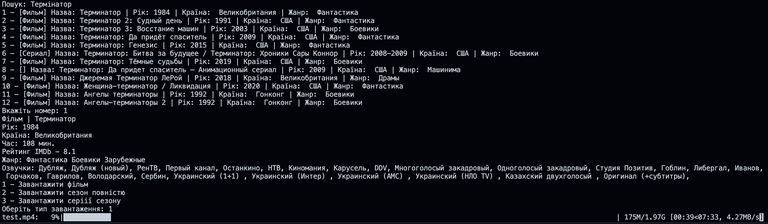
This is what I achieved:
I'll add the actual code and explanations regarding the algorithm in the next article on this topic.
Всім привіт, я не пірат і ніколи таким не був. Та мені набридло передивляючи фільми перезавантажувати сторінку, отримувати постійні стопи у конекті через те що у мене поганий інтернет. Бо фільм з сайтів не завантажується повністю доки він на паузі, а лише приблизно на 5 хвилин, у деяких 15-20 хвилин. Але далі якщо з'єднання було зупинено він перестає це робити. Торент теж не вихід, бо розповсюдження не ліцензійного контенту заборонено за законом.
Тож назад до теми. Як відбувається завантаження фільму? Це не цілий великий файл як ми звикли бачити по 3-8 гігабайт а малі шматочки які є байт строкою у отримуваному пакеті, зазвичай стандарт по 30 секунд на 1 такий пакет данних, і цих шматків може бути багато, декілька тисяч на 1 фільм (уявіть скільки запитів тримає сервер на якому вони лежать). По перше ваш браузер відправляє GET запит на цей сервер, у відповідь отримуючи байт строку у якій якраз і закодовано цей шматочок фільму, там вже є і звукова доріжка, і субтитри (тому коли ви тицяєте на кнопку з субтитрами вони можуть не відразу з'являтись). Плеєр через який це все відбувається має вже алгоритм який з цієї байт строки відтворить відео файл, звукову доріжку та субтитри, помістить це у ОЗУ (тепер зрозуміло чому ютуб вкладка може займати 1.5 гігабайти).
Коли ми це знаємо, тепер нам треба взяти за основу якийсь сервіс, я візьму всім знайому HDRezka буду писати замість посилання щоб не рекламувати цей сервіс просто domain. Сам алгоритм доволі простий, перший етап це знайти запит пошуку фільмів:
uri: domain/engine/ajax/search.php,
PARAMS:
{
"q": "Terminator"
}
У відповідь ми отримуємо назву та посилання на сторінку з цим фільмом. Але воно у HTML вигляді. Наступним кроком я застосував бібліотеку bs4 для парсингу html який ми отримали.
У посиланні є код фільму який відповідає запису у базі даних "domainfilms/horror/57276-astral-5-krasnaya-dver-2023.html", ось саме 57276 нас і цікавить але про це далі. Також тут вже знаходиться вся інформація про кожен фільм, локалізації і тд (розумна архітектура, згодні?) тому це спрощує наступну операцію.
Знаючи усі вхідні данні які нам необхідні, йдемо вже до наступного GET запиту, а його я знайшов вже перейшовши на сторінку з фільмом:
uri: domain/ajax/get_cdn_series/?t=timestamp
PARAMS:
{
"id": ,
"translator_id": ,
"favs": ,
"season": ,
"episode": ,
"action": ,
}
Після цього запиту ми отримуємо ті самі лінки на кожну частину необхідного фільму.
Ось що в мене вийшло:
Сам код, та поясненя щодо алгоритму я додам у наступній статті на цю тему.
Congratulations @stropikaro! You have completed the following achievement on the Hive blockchain And have been rewarded with New badge(s)
Your next target is to reach 300 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out our last posts: